To reserve or not to reserve - that is the question... ( as Shakespeare so eloquently put it).
If you're looking to save money when running applications in Azure then one of the easiest and least impactful ways is to 'reserve' resources. I'll be talking here about IaaS resources but other resources have this capability too - though savings might not be as dramatic as with IaaS.
A reservation is a commitment to buy essentially - by making that commitment you get it for a much reduced price over the normal pay as you go price - this can be over a 1 or 3 year timeframe and can attract substantial (up to 80% for long reservations on certain machine types).
Now the problem for us has always been how to effectively manage this - we have a huge volume of servers and the initial approach we followed was for each application owner to agree to a long commitment - we would then scope the reservation to that applications resource group so they were guaranteed as the ones that would get the discount. This works fine in the simple case of a few servers but just does not effectively scale to thousands of servers - there is just way too much overhead to manage.
Instead we decided to take a different tack - bulk reservations tenant wide.
This means we can't ensure who will get the reservation discount (as the discount will jump around between eligible servers) but it means as an organisation overall we get the savings without a massive management overhead.
Now the question is how many servers should we bulk reserve?
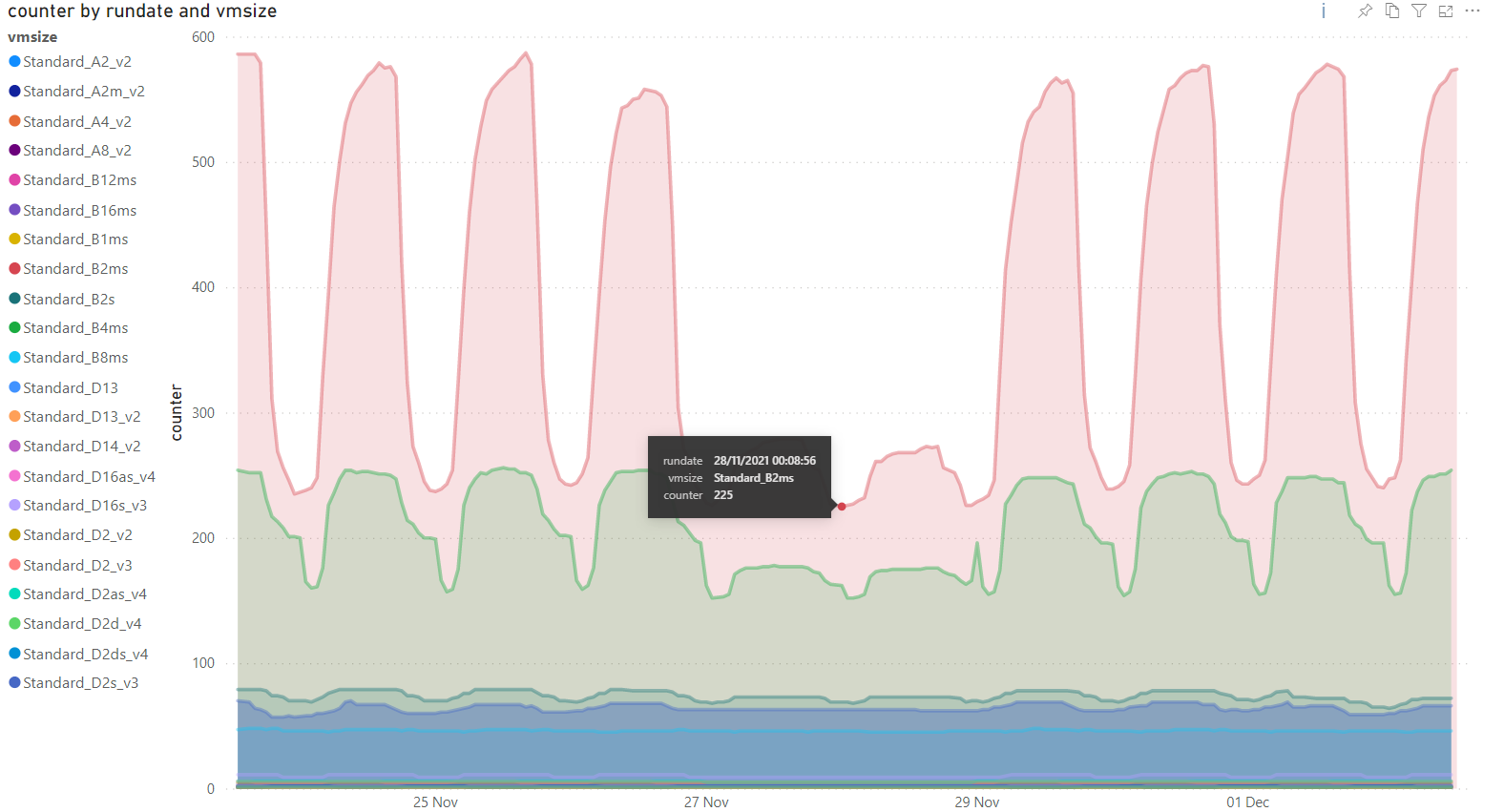
The reservations screen itself does offer some recommendation but this does not seem to take into account partially running machines (of which we have lots) to really give the best guess at how many we should have to maximize the savings. So to remedy this we built a small logic app to store some stats into a SQL database which we can then query in powerbi - this allows us to produce graphs like this:
With this data we can then show the 'minimum' number of servers of a certain size we have running within a time period - this is then a baseline number for reservations we should take out. In the example above we always have at least 225 B2ms machines running so should bulk reserve that many. With some additional maths we can probably up that number further as if we assume that a reservation saves at least 30% over PAYG costs then even if the reservation is unused 30% of the time it still saves money overall when it is used ( I just need to work out that additional bit of maths.....)
To give the background on what was built to create this it was actually pretty simple - we had a pre-existing 'utility' Azure SQL database in to which we added another table
The definition (generated from SQL mgmt studio) is this
/****** Object: Table [dbo].[runningservers] Script Date: 02/12/2021 14:47:15 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[runningservers](
[id] [int] IDENTITY(1,1) NOT NULL,
[rundate] [datetime] NULL,
[vmsize] [varchar](100) NOT NULL,
[counter] [int] NULL,
PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
So this is really simple - just a surrogate primary key along with 3 columns we are interested in - the date the count ran, the vmsize and the count of running machines (note that its running machines and not just existing machines - that's an important distinction)
Once we have that empty table we just need something to populate it - here I'm just using a very simple logic app - this will perform a resource graph query against all of our estate and then dump the results in this SQL Server table.
That logic app definition looks like this:
Steps being
1) trigger on a timer every hour
2) make rest call to resource graph to retreive the counts
3) parse the json output that is returned
4) open a loop
5) for each 'row' in the dataset insert it into the SQL database
Point 1 is very simple and doesn't warrant more explanation
the only change being the query that is executed - I've included that below as it's a little long - note that it all has to be a 'single' line when pasted in to the http body element - it can't cope with newline characters
{
"query": "resources| where type =~ 'microsoft.compute/virtualMachines' |project vmSize = coalesce(tostring(properties.hardwareProfile.vmSize), '-'),subscriptionId, powerState = tostring(split(tolower(properties.extended.instanceView.powerState.code), 'powerstate/')[1]),provisioningState = tostring(properties.provisioningState) | project vmSize, status = case( provisioningState =~ 'CREATING', 'Creating', provisioningState =~ 'DELETING', 'Deleting', (provisioningState =~ 'FAILED' and isnotnull(powerState) and isnotempty(powerState)), case( powerState =~ 'RUNNING', 'Running', powerState =~ 'STOPPED', 'Stopped', powerState =~ 'DEALLOCATED', 'Stopped (deallocated)', 'Unknown' ), provisioningState =~ 'FAILED', 'Failed', (provisioningState =~ 'SUCCEEDED' and isnotnull(powerState) and isnotempty(powerState)), case( powerState =~ 'RUNNING', 'Running', powerState =~ 'STOPPED', 'Stopped', powerState =~ 'DEALLOCATED', 'Stopped (deallocated)', powerState =~ 'STARTING', 'Starting', 'Unknown' ), (provisioningState =~ 'UPDATING' and isnotnull(powerState) and isnotempty(powerState)), case( powerState =~ 'DEALLOCATING', 'Deallocating', powerState =~ 'RUNNING', 'Running', powerState =~ 'STARTING', 'Starting', powerState =~ 'STOPPING', 'Stopping', 'Updating' ), 'Unknown' ),subscriptionId | where status=='Running' |summarize count() by vmSize"
}
Point 3 needs a slight explanation as you'll need the schema value to be able to parse the output from the previous step - this schema looks like this:
{
"properties": {
"count": {
"type": "integer"
},
"data": {
"items": {
"properties": {
"count_": {
"type": "integer"
},
"subscriptionId": {
"type": "string"
},
"vmSize": {
"type": "string"
}
},
"required": [
"vmSize",
"count_"
],
"type": "object"
},
"type": "array"
},
"facets": {
"type": "array"
},
"resultTruncated": {
"type": "string"
},
"totalRecords": {
"type": "integer"
}
},
"type": "object"
}
So when pasted in the definition should look something like this:
The final part (the inserting of the data) is done using the insert row action - when defined this will look something like this (note I derive the current time from utcnow(), the other columns come from the resource graph query):
So at this point everything is done and we insert fresh data every hour ( I know reservations are checked every 30 mins but our shutdown tags always operate on round numbers of hours - you could up the frequency to every 30 mins if need be). You could also add in the extra dimension of subscription to the query/insert if that is relevant for you.
Now all that remains is to visualize the data - you can simply do it in SQL if that suits you or you can graph it up in powerbi or whatever your weapon of choice is. I'm by no means an expert at powerbi but i could manage to get the simple graph of what i needed to do in just a few clicks.
We're holding fire on bulk reservations for a little while to complete two other important activities which directly link into reservations:
1) Make sure the machines autoshutdown tags are set correctly - in many cases starting/stopping machines can result in fewer running hours and even greater discount than reservations
2) rightsizing and right'series'ing - making sure that the machine is not too big - but also making sure it's on the latest series of machines - for example make sure Dv2 machines are moved up to Dv4 (or even v5) if possible - nothing that newer series may not have reservation options (yet)
Once those are complete we will proceed with a bulk reservation which should result in a huge saving (as will point 1 and point 2 above).
Once reservations are in place - we could then start graphing that too to check the reservations are aligned with the usage.




It depends on the situation Hosting Raja reserve if it adds value, otherwise don't.
ReplyDeleteThis comment has been removed by the author.
ReplyDelete