When i run a parallel datapump import of a schema what does datapump actually do to parallelize the process?
If a simple impdp is run with parallel=6 (chosen at random) the process runs as follows:
1) the initial part of the import is serial while it loads the master table and create a number of objects inside the database (including empty tables) - see section 1 in picture below
2) the next part of the import users the 6 slaves it created, each slave loading a single table serially, as soon as a slave finishes a table it picks the next one from the master_table - the tables being loaded largest first according to the information stored in the master_table when it took the export. As you can see below in section 2

3) Once the tables are all finished (and all of them do have to be finished) it will move on to indexes, instead of each slave creating its own index a single index is created in parallel and the process moves on though all the indexes in this fashion

4) once the indexes are finished the process then moves on to other objects which are done serially (other than bitmap indexes which are done separately from the btree indexes). The export then carries on to completion removing the master table as its last activity.
 Parallelism can be altered during the process (either up or down) but may not take effect until the completion of the current object.
Parallelism can be altered during the process (either up or down) but may not take effect until the completion of the current object.
If a simple impdp is run with parallel=6 (chosen at random) the process runs as follows:
1) the initial part of the import is serial while it loads the master table and create a number of objects inside the database (including empty tables) - see section 1 in picture below
2) the next part of the import users the 6 slaves it created, each slave loading a single table serially, as soon as a slave finishes a table it picks the next one from the master_table - the tables being loaded largest first according to the information stored in the master_table when it took the export. As you can see below in section 2

3) Once the tables are all finished (and all of them do have to be finished) it will move on to indexes, instead of each slave creating its own index a single index is created in parallel and the process moves on though all the indexes in this fashion
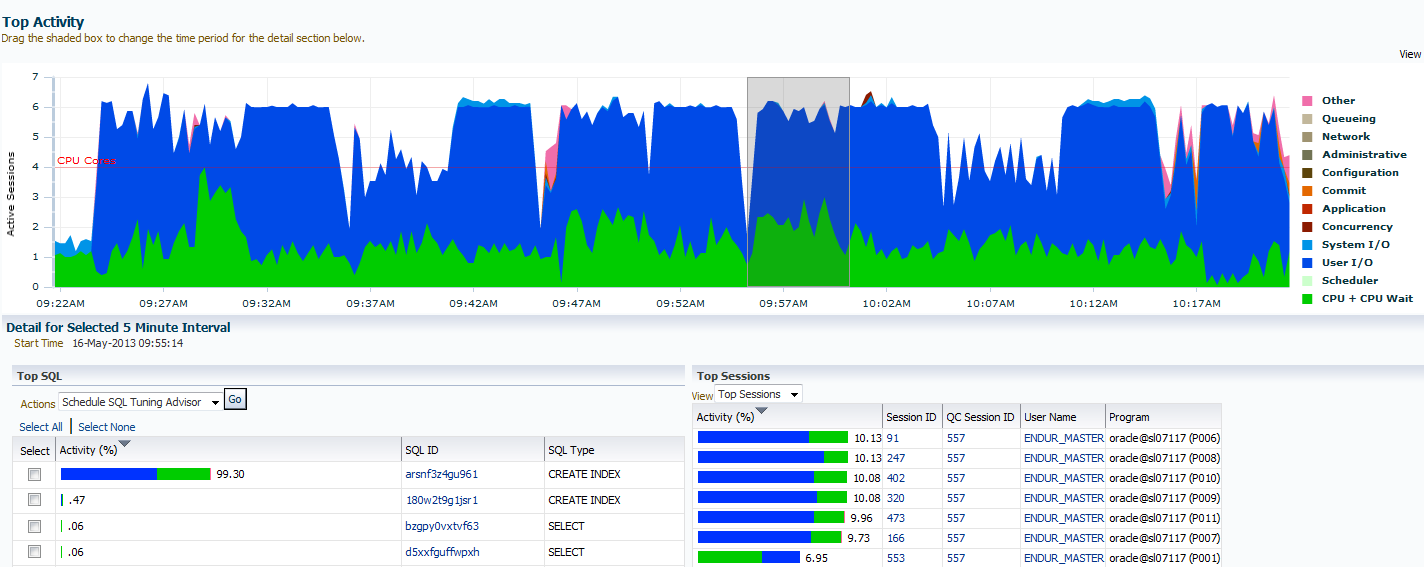
4) once the indexes are finished the process then moves on to other objects which are done serially (other than bitmap indexes which are done separately from the btree indexes). The export then carries on to completion removing the master table as its last activity.

Comments
Post a Comment